Developing a video distribution platform from scratch
September 01, 2025
I recently built something I’ve always wanted to play with, a video sharing platform. Working with video is challenging because it involves long-running processing tasks and the need to handle large data transfers. These challenges force you to design quite complex architectures, which is exactly what made this project exciting for me. In this article, I will walk through how Core Cast is built and why it turned out to be such a valuable learning experience.
Core Cast general walkthrough
You can see how Core Cast works in the video demo here, you can also access the code here. At first glance it looks like a basic video app, but behind the scenes it runs on a quite complex backend.
To give you a quick preview of what’s inside, Core Cast includes:
- A custom resumable upload system with support for distributed deployments
- A video processing pipeline built on top of FFmpeg
- An embedding-based recommendation system powered by vector databases
- Scalable tracking and aggregation of views and likes
In the rest of this article, I will walk through how each piece is built and the lessons I learned along the way.
How VOD streaming works at a high level
To understand how Core Cast is built, it helps to first look at how video on demand (VOD) streaming works at a high level. Imagine a platform like YouTube or Core Cast.
Users begin by uploading videos through a chunked upload system (I’ll explain the details later). The platform then transcodes each video into a streamable format such as HLS or DASH. These formats/protocols support multiple renditions (480p, 720p…) and distribute video in chunks.
The resulting video chunks and playlists are uploaded to a CDN and delivered to end users. On the client side, a player like Hls.js requests the appropriate chunks and stitches them together for smooth playback.
This is a simplified overview, I hope you get the general idea about how video goes from uploader to audience.
System architecture
Now that we are on the same page regarding the basics of VOD distribution and my intentions with core cast. I will start covering how core cast services architecture works.
Core Cast uses a microservices architecture composed of 4 backend services and the frontend. These backend services are separated based on concerns and technical requirements. The system is ready to work with N instances of each service except the housekeeping service that must include a single instance.
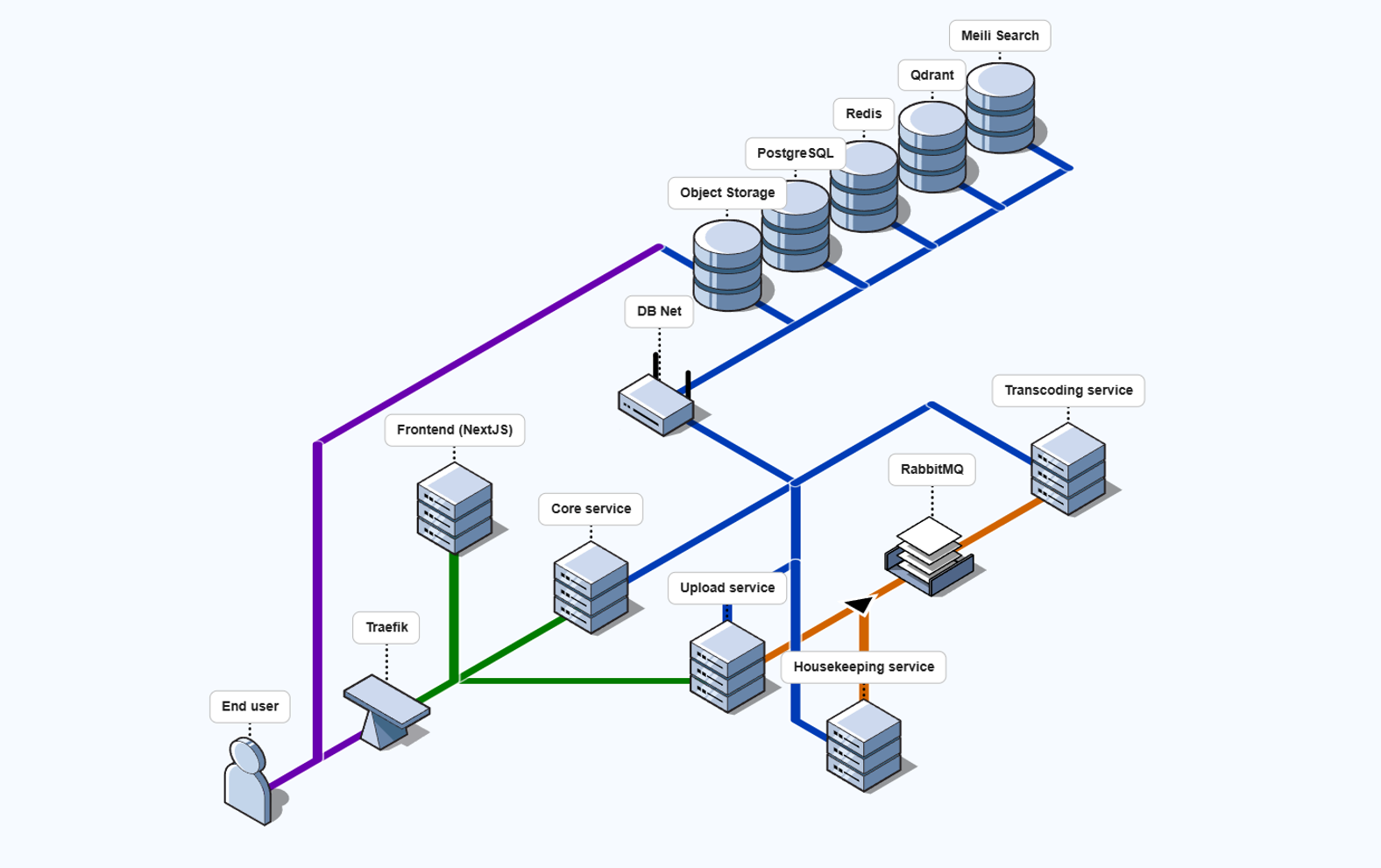
Core service
The most important service is the core service this is the one in charge of every API call that’s not uploading videos. It does things like authentication or video metadata distribution. You could decouple this service into many small microservices (auth, distribution, recommendation…) but it doesn’t make a lot of sense for this use case.
Upload service
The Upload Service manages multipart, resumable uploads. This service requires a server with a strong network connection. I will cover how these multipart uploads work later.
Transcoding service
After a video is uploaded, it is added to the processing queue. The Transcoding Service transcodes the video into multiple resolutions, generates HLS chunks and playlists, generates a preview clip and thumbnail, produces metadata embeddings for recommendations, and uploads the results to the CDN.
This service requires a high-end GPU so you can leverage GPU based video codecs such as NVENC to improve transcoding speed. I hope you start seeing why this is one of the best use cases of microservices. Not only do we separate concerns but also hardware requirements.
Housekeeping service
The Housekeeping Service oversees the RabbitMQ queue and the video processing task registry in Postgres, ensuring that no tasks are lost if a transcoding instance goes down. It is also responsible for batching likes and views and sending them from Redis to ClickHouse and Postgres. I will cover this in detail later.
Databases
As you can see, there’s a lot of databases 6 in total (ClickHouse is missing in the diagram). Each one serves a purpose, and I wanted to play around with multiple DBs in the same project. You could also use Postgres as the vector database or with plugins for time-based records such as Timescale DB and simplify the system.
Key features technical deep dive
Now that you know how Core Cast is distributed across services. Let’s cover how some of the key features work in detail.
Chunked resumable uploads
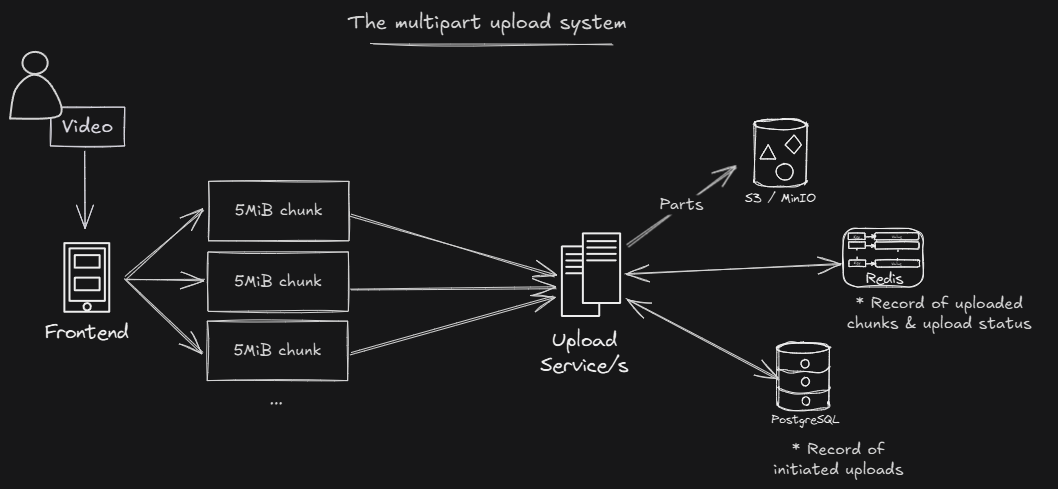
Videos are large files and uploading them over HTTP requires a multipart approach. This means splitting the file into smaller chunks on the client and sending each chunk in a separate PUT request to the server.
Using this approach also enables resumable uploads. If a user closes the app during an upload, they can resume later and only the remaining chunks need to be sent.
Core Cast’s Upload Service implements a custom multipart upload system on top of S3. It automatically uploads chunks using the S3 Multipart Upload API and supports resuming interrupted uploads. The service does not reassemble files, S3 does. The Upload Service’s job is to track chunks and metadata so the upload can be completed correctly on S3 and users can resume unfinished uploads.
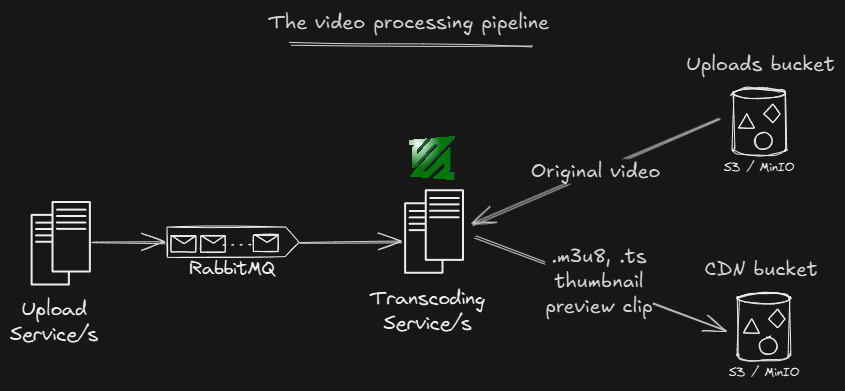
Transcoding pipeline
Once a video has been uploaded, a processing task is generated and sent to RabbitMQ. The Transcoding Service listens to RabbitMQ and picks up these tasks.
The service relies on FFmpeg for all media-related operations. First, it validates the uploaded video for compliance, then generates a thumbnail and preview clip.
The main function of the pipeline is to create an adaptive bitrate (ABR) ladder and package the video into HLS. The video is transcoded into multiple resolutions and bitrates. For each step in the ABR ladder, the service generates a series of .ts video chunks and an .m3u8 playlist for that resolution. These playlists are then combined into a master playlist that the video player can use to select the optimal quality for the viewer.
Finally, all generated assets including preview clips, thumbnails, video chunks, and playlists are uploaded to an S3 or MinIO bucket for distribution to the end users. Now we can remove the original video and keep only the HLS version.
Embedding based recommendations & full text search
Core Cast leverages text embeddings generated from video titles and descriptions to perform similarity searches. These embeddings are stored in a vector database, in this case Qdrant.
Qdrant allows you to provide an embedding and quickly find similar entities. This technology is very powerful and worth exploring if you haven’t worked with vector databases before.
Using this system, Core Cast can easily generate video recommendations based on what a user is currently watching (side recommended videos). For the main video feed, I combine this with a cookie that tracks recently watched videos, which allows the system to suggest content that is both relevant and personalized. This serves as a simple recommendation system that’s quite performant and easy to implement. In addition to embedding-based recommendations, Core Cast implements full-text search using Meilisearch.
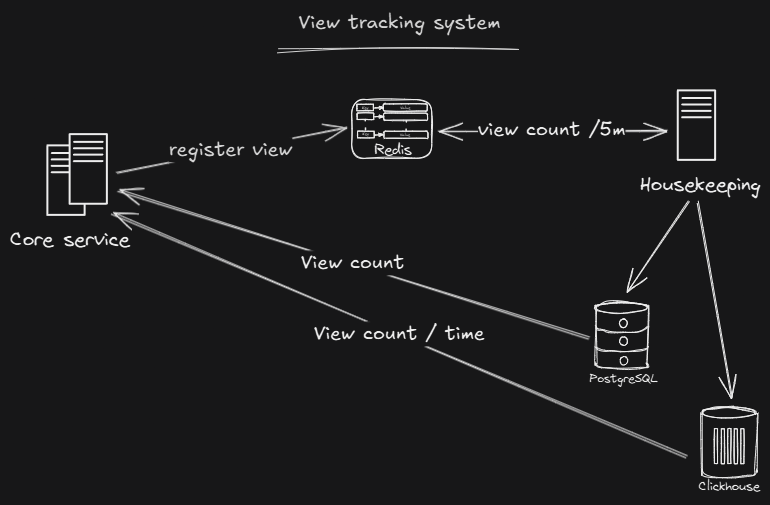
Tracking views at scale
Core Cast uses a batching approach to track video views efficiently. When a user watches a video, it increments a counter in Redis. These updates are extremely fast, avoiding bottlenecks even under high traffic.
The Housekeeping Service runs a task every five minutes to collect all view counts from Redis and send them to ClickHouse. This approach combines the speed of Redis with the analytical power of ClickHouse, allowing creators to get precise view statistics without slowing down the system.
For end users, view counts are displayed by updating interaction records in Postgres, which store both likes and views. The system does not perform a single aggregation query to retrieve this data, and all results are cached for faster access.
While this system works, it is not fully polished and is challenging to test. There is plenty of room for improvement, especially if the platform scales to many videos due to how records are retrieved from Redis. However, the current design could likely handle a large number of users effectively.
Takeaways and thoughts
Building Core Cast was a great learning experience. I’ve explored more about microservices and distributed architectures with what I believe is a perfect project for that.
This project reinforced that building even a minimal video platform involves understanding distributed systems, media processing, and scalable architecture. Core Cast may lack the polish of a production-grade system, but it successfully demonstrates the core concepts behind modern video platforms and serves as a solid foundation for further experimentation or learning.
If you’re interested in video platforms, distributed systems, or digital twins & IoT, bookmark my blog to stay updated. I’m working on some exciting projects that I can’t wait to share with the world soon. You can also follow me on X or connect with me on LinkedIn